
Sometimes an app gets an update and your phone suddenly slows down, even though nothing major changed. Now imagine if the same app was rebuilt to be lighter and faster, so it actually worked better on your phone. That’s the basic idea behind LLMs and SLMs.
LLMs are big and powerful AI models. They can do a lot, but they need strong computers and usually run on large servers. They are impressive, but you can’t really run them on everyday devices. SLMs on the other hand are smaller versions. They’re lighter, faster, and made to run well on standard hardware like phones or laptops. They don’t do everything, but they do the important things quickly.
It’s like the difference between carrying a huge encyclopedia and a small pocket guide. The encyclopedia has more information, but the pocket guide is easier to carry and is usually enough for daily needs.
What are Small Language Models?
Small Language Models (SLMs) are smaller AI models built with fewer parameters, which makes them faster and easier to work with. Instead of trying to handle every possible situation like large models do, SLMs are usually trained on more focused datasets. This helps them perform really well in specific tasks.
Because of their lean design, SLMs are:
- Efficient that require less compute power, memory, and energy.
- Customizable which is easier to fine-tune for industry- or task-specific use cases.
Practical in environments where running massive AI models is not feasible, such as on edge devices, internal business tools, or low-resource systems.
In simple terms, SLMs are specialists. They don’t try to do everything, but they do their chosen tasks very effectively without the heavy cost and complexity of a large model.
Architecture of Small Language Models
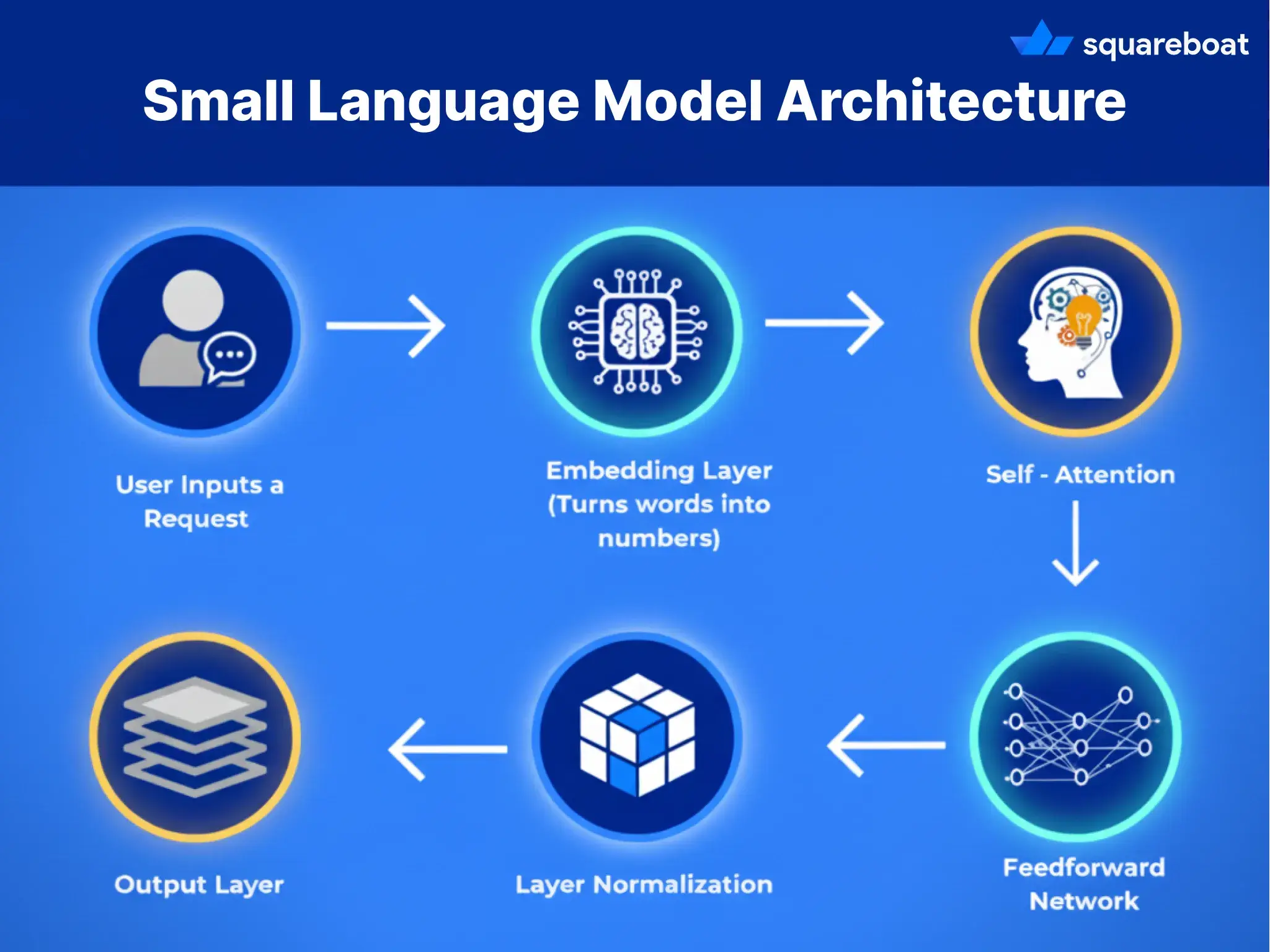
Small Language Models (SLMs) use the transformer architecture, the same backbone that powers today’s generative AI models. The difference lies in how they’re scaled down: fewer parameters, lighter layers, and optimizations that make them leaner without losing their usefulness.
Let’s break down the core components in simple terms:
1. Self-Attention Mechanism:
- This allows the model to decide which words (or tokens) in a sentence are most important to each other.
- For example: in the sentence “The cat sat on the mat because it was tired”, the model needs to understand that “it” refers to “the cat,” not the mat.
Self-attention acts like a spotlight, highlighting the words that matter for context while dimming the rest.
2. Feedforward Neural Networks:
- Once attention has filtered the important information, feedforward layers process it quickly and efficiently.
- Think of this as the model’s “decision engine” — it takes the spotlighted words and runs them through small mathematical functions to generate the right output.
In practice, this is y an SLM can complete tasks like spam detection or text summarization at high speed without heavy computing.
3. Layer Normalization
- Just like an engine needs oil to run smoothly, normalization ensures the training process stays stable.
It balances out values inside the model so it doesn’t “overheat” on certain tokens and produces consistent results.
4. Embedding Layers
- Before the model can even start, words are converted into numbers (vectors) so they can be processed mathematically.
- These embeddings capture meaning — for instance, the words “doctor” and “nurse” will have closer vector values than “doctor” and “banana.”
5. Output Layer
- Finally, the model takes all this processed information and generates the result — whether it’s predicting the next word, classifying spam, or giving a recommendation.
Example in action:
- A Large Language Model (LLM) might try to answer any question from Shakespeare to stock prices, requiring billions of parameters.
- An SLM designed for customer support only needs to focus on a narrower dataset (FAQs, past chat logs). Its architecture processes just what’s relevant — meaning faster, cheaper, and still highly accurate for that use case.
How Are Small Language Models Made?
SLMs are built by optimizing existing architectures rather than designing new ones. Techniques like parameter reduction, knowledge distillation, and task-specific fine-tuning are used. That result in a more practical model tailored for specific tasks or resource-limited environments. Three key techniques are commonly used to build SLMs:
1. Distillation – Teaching a Small Model from a Big One
- A large “teacher” model trains a smaller “student” model by transferring its knowledge.
- The smaller model learns to mimic the outputs of the larger one but with far fewer parameters.
Example: A giant LLM like GPT could distill into a smaller chatbot that only answers customer support questions, running smoothly on limited hardware.

2. Quantization – Compressing Model Weights
- Model parameters (which are usually stored in 32-bit floating point numbers) are converted into lower precision formats like 8-bit or even 4-bit.
- This reduces memory use and speeds up inference with minimal loss in accuracy.
Example: Running a quantized SLM on a smartphone for real-time voice transcription without draining the battery.

3. Pruning – Cutting Out What’s Not Needed
- Unnecessary weights or connections in the network are removed, like trimming branches from a tree.
- This makes the model leaner while keeping performance close to the original.
- Example: An SLM for email spam detection can prune away parameters unrelated to classification, making it faster for real-time filtering.

LLMs vs SLMs Explained Simply
Large Language Models (LLMs) and Small Language Models (SLMs) serve different purposes in the AI ecosystem. While LLMs are powerful generalists, SLMs are efficient specialists.
Understanding their differences helps organizations choose the right tool for the job.
Aspect | Large Language Model | Small Language Model |
Size and Parameters | Billions → hundreds of billions | Millions → a few billion |
Training Data | Vast, general-purpose datasets | Smaller, domain-specific datasets |
Infrastructure | Requires GPUs/TPUs, large memory & clusters | Runs on modest hardware, even edge devices |
Speed & Latency | Slower, heavy inference time | Faster, optimized for real-time tasks |
Energy & Cost | High compute and Energy costs | Lower compute, cost-effective |
Capabilities | Broad knowledge, general-purpose | Task-specific, specialized |
Customization | Harder, expensive to fine-tune | Easier and quicker to fine-tune |
Use Cases | Research, creative writing, multi-domain chatbots | Spam filters, voice assistants, recommendation engines |
Real World Examples:
1. Smart Keyboards (Predictive Text & Autocorrect)
Think about how your phone predicts the next word while you’re typing a message or fixes your spelling mistakes instantly. Apps like Gboard and SwiftKey run on-device small language models.
- They’re trained on huge amounts of text but compressed into a lightweight form that fits on your phone.
- Because they run locally, they don’t need the internet — making typing smoother, faster, and private.
Imagine if they relied on a massive LLM in the cloud — every keystroke would need an internet call, making the experience painfully slow.
SLMs make everyday typing feel natural, while keeping your data safe.
2. Healthcare Assistants
In hospitals and clinics, small language models are quietly powering apps that summarize patient notes, suggest medical coding, or assist with symptom checking.
- For example, an SLM can be trained only on a hospital’s patient record formats and common procedures.
- Doctors don’t need a ChatGPT-level model that “knows everything” — they need a fast, accurate, and specialized assistant that runs securely on local infrastructure.
- By being lightweight, SLMs protect patient data, reduce costs, and make AI usable in resource-constrained clinics.
SLMs make AI practical for life-saving decisions without the infrastructure burden of giant LLMs.
3. Fraud Detection in Banking
Every second, banks process millions of transactions. An LLM would be too slow and costly to monitor this in real time. Instead, banks deploy SLMs fine-tuned on transaction patterns to flag suspicious activity.
- For example, if your card is suddenly used in another country minutes after you bought groceries at home, the SLM spots the anomaly instantly.
- These models don’t need to generate essays or conversations — they just need to be laser-focused on fraud detection.
- Because they’re smaller, they can run directly in the bank’s systems, ensuring real-time alerts without expensive infrastructure.
SLMs keep your money safe by being fast, specialized, and efficient.
Key Characteristics of Small Language Models
1. Compact Size
- SLMs have significantly fewer parameters compared to LLMs (millions instead of billions).
This makes them lightweight and capable of running on devices like smartphones, laptops, or edge servers.
2. Task Specialization
- Unlike LLMs, which are general-purpose, SLMs are designed for narrow, specific tasks such as translation, spam detection, or predictive text.
- This “specialist” nature keeps them efficient while maintaining accuracy.
3. Lower Resource Requirements
- SLMs demand far less in terms of computational power, memory, and storage.
- They can run in environments where an LLM would be impractical (e.g., offline apps, IoT devices, hospitals with limited infrastructure).
4. Faster Inference
- Because of their smaller size, SLMs deliver results with low latency.
- Example: autocomplete suggestions appearing instantly as you type, without delays.
5. Energy Efficiency
- Training and running SLMs consume much less energy compared to LLMs.
- This makes them sustainable and cost-effective for businesses at scale.
6. Customizability
- SLMs can be fine-tuned quickly on domain-specific data (like medical records, legal documents, or financial transactions).
They don’t need vast internet-scale datasets to be useful.
7. Privacy-Friendly
- Since they can run locally, SLMs minimize the need to send sensitive data to external servers.
Ideal for healthcare, finance, and personal devices where privacy is critical.
Timeline of Small Language Models
2017 – The Transformer Era Begins
- Paper: Attention Is All You Need introduces the Transformer architecture, the foundation of all modern language models.
- No “small” models yet, but this sparks the idea of scaling both up (LLMs) and down (SLMs).
2018–2020 – First Wave of Compact Models
- DistilBERT (2019): Compressed version of BERT, 40% smaller but nearly as accurate.
- TinyBERT (2020) : Designed for mobile and edge devices, maintaining strong accuracy with minimal size.
- MobileBERT (2020) : Tailored for smartphones, optimized for speed and memory efficiency.
- These models prove distillation and pruning can make transformers lightweight and practical.
2021 – On-Device AI Becomes Real
- ALBERT (2021) : A “light” version of BERT with fewer parameters, focused on efficiency.
- MiniLM : Smaller, task-specific model with fewer layers but strong performance.
- Deployed widely in consumer apps: Gboard predictive typing, Offline Google Translate, Siri/Alexa on-device commands.
- Marks the point where SLMs enter everyday life.
2022 – Expanding Scope: Multilingual & Domain-Specific
- mBERT & XLM-R small versions : Support multiple languages with reduced size.
- Research into domain-specific SLMs: Healthcare (clinical note summarization) , Finance (transaction anomaly detection).
- In parallel, LLMs like Bloom and Galactica demonstrate scale, but compressed SLM variants show practical use in constrained settings.
2023 – Task-Specific and Efficient Models
- Pythia (2023) → Open-source model suite with different sizes, enabling “choose-your-scale” training.
- Cerebras-GPT → Trained efficiently on Cerebras hardware, showing how smaller models can still be powerful for coding and logic tasks.
- OPT-IML (small variants) → Meta’s efficient models optimized for specific tasks.
Industry adoption grows: SLMs in chatbots, coding assistants, and recommendation systems.
2024 & Beyond – The Age of Edge SLMs
- Quantization (shrinking models further without losing accuracy).
- Pruning & modular architectures (drop what you don’t need).
Retrieval-Augmented SLMs (stay small, but fetch domain knowledge when needed).
How to Use DistilBERT & MiniLM :
1. DistilBERT
- Overview: Compressed, distilled version of BERT. About 40% smaller while retaining ~97% of its performance.
- Key Strengths: Lightweight, fast, easy to fine-tune. Ideal for text classification, sentiment analysis, and Q&A tasks.
Use Cases: On-device NLP, chatbots, and lightweight enterprise AI applications.
How to use DistilBert :
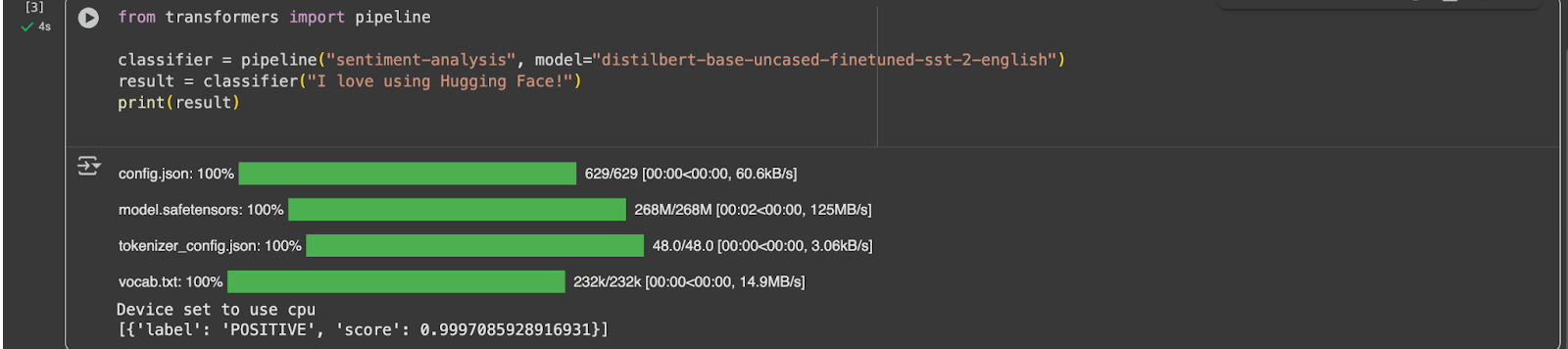
Using Hugging Face Transformers
label = the predicted sentiment (POSITIVE or NEGATIVE).
score = the model’s confidence (close to 1 = very confident).
This code uses a small, efficient language model (DistilBERT) fine-tuned on a sentiment dataset to decide whether a sentence expresses something positive or negative.
2. MiniLM
- Overview: Small transformer model designed for high efficiency with minimal layers.
- Key Strengths: Very compact, yet competitive in accuracy; optimized for embeddings, semantic search, and natural language understanding tasks.
Use Cases: Enterprise search engines, document understanding, recommendation systems.
How to use MiniLM:
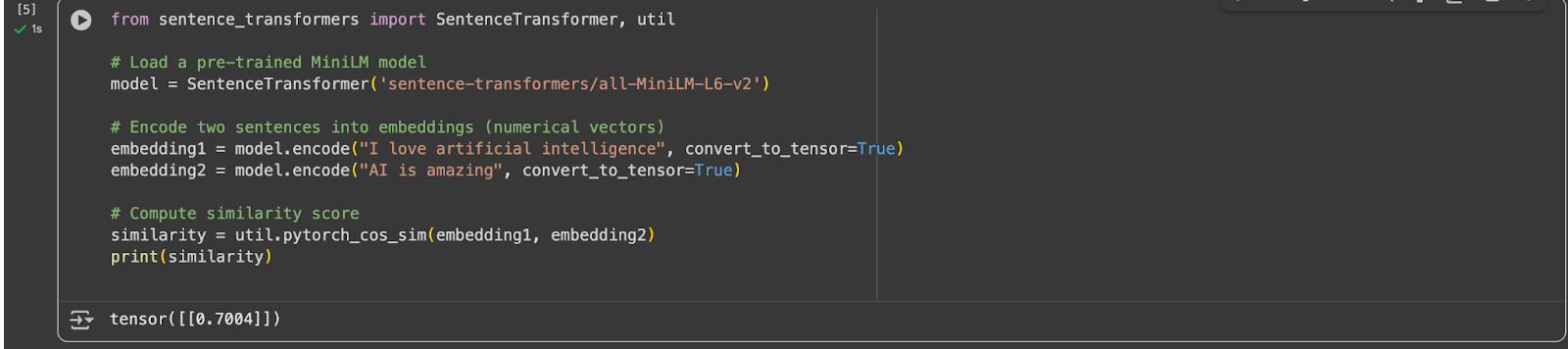
The output similarity will be a score between 0 and 1.
Close to 1 → sentences mean almost the same.
Close to 0 → sentences are unrelated.
This means the model thinks “I love artificial intelligence” and “AI is amazing” are highly similar (70%).
Final Thoughts
SLMs don’t replace LLMs they complement them instead. Where speed and privacy matter most, SLMs shine. Where broad knowledge, deep reasoning, and creativity are required, LLMs still dominate.
Working with experienced AI developers can help you pick the right approach, whether it’s using SLMs, LLMs, or a combination, to get the most out of your AI projects.
In many ways, the future of AI won’t be about choosing big vs. small, but about using the right-sized model for the right problem. Just like we carry a smartphone for daily tasks and rely on supercomputers for complex research, SLMs and LLMs will co-exist for solving problems in their own way.
Frequently Asked Questions
Q. What are the key differences between SLM and an LLM?
The main difference between SLM and LLM lies in size, scope, and purpose. Small Language Models (SLMs) are compact and designed for specific tasks, making them fast and lightweight enough to run on everyday devices. Large Language Models (LLMs), on the other hand, are massive, general-purpose models capable of handling broad knowledge, complex reasoning, and creative outputs, but they require powerful servers, high memory, and significant computational resources to function effectively.
Q. How do I choose between an SLM and an LLM for my project?
Choosing between SLMs and LLMs depends on the project’s goals, resources, and constraints. SLMs are ideal for cost-effective and task-specific applications where privacy and efficiency are priorities. LLMs are better for projects that require broad knowledge, creative output, or complex reasoning. Taking help from experts’ consultation can help determine whether a small, large, or hybrid model approach will deliver the best performance and ROI for your specific use case.
Q. How can expert AI development services help me implement SLMs and LLMs in my business?
When you choose experienced AI development teams, you get experts who can handle model selection, customization, fine-tuning, and deployment, making AI integration more efficient and cost-effective. They also optimize performance for your hardware and ensure privacy and security standards are met.
Q. Can SLMs do the same things as LLMs?
SLMs cannot fully replace LLMs because they are designed for focused tasks rather than general intelligence. While SLMs perform specialized functions such as predictive text, spam detection, or summarizing structured data efficiently, LLMs can address a wide array of topics, generate detailed content, and solve complex reasoning problems.
Q. Why should I use an SLM instead of an LLM?
SLMs are the ideal choice when speed and cost-effectiveness matter. They can run on devices like laptops, smartphones, or edge servers without requiring heavy cloud infrastructure. Additionally, because SLMs can process data locally, they enhance privacy and reduce security risks, making them well-suited for sensitive environments such as healthcare, finance, or internal enterprise applications where sending data to a remote server may be undesirable.
Q. Are SLMs accurate even though they are smaller?
Yes, SLMs can achieve high accuracy for their specific tasks. Through techniques like distillation, pruning, and quantization, these models retain most of the performance of larger LLMs in a narrower domain. While they may not handle every topic or generate creative outputs like LLMs, they are extremely reliable for targeted applications.
Q. Can SLMs be customized for my business needs?
Absolutely, one of the advantages of SLMs is their adaptability. They can be fine-tuned quickly on domain-specific datasets such as medical records, legal documents, and financial transactions. This allows businesses to create highly specialized AI tools without the massive cost, computational requirements, or complexity of training a full-scale LLM, ensuring fast, accurate, and relevant results tailored to the organization’s unique needs.
Q. Can SLMs run on smartphones or edge devices?
Yes, SLMs like DistilBERT, MiniLM, and MobileBERT are specifically optimized to operate on mobile phones, tablets, laptops, or edge devices. Their compact size and efficiency enable AI-powered features such as predictive typing, voice recognition, and text summarization without relying on cloud infrastructure. This makes AI accessible, fast, and private, even in devices with limited computational power and memory.
Anubhav Jain is a Technical Lead with 6+ years of experience building scalable web and mobile apps. At Squareboat, he drives engineering, architecture, full-stack development, and technical excellence to ensure smooth, high-quality project delivery.
