
Modern airplanes are built with resilience at their core. If one engine fails mid-flight, the plane doesn’t drop from the sky instead it continues safely on the other. That’s the essence of fault tolerance: anticipating failure and ensuring it doesn’t disrupt the journey.
Have you ever paused to think about fault tolerance in the frontend layer?
We often associate system design practices with backend layers and databases, but what about our frontend?
Stateless scalability - a concept often overlooked, is actually what makes the frontend resilient to failure. While the debate between stateful and stateless frontends continues, the reality is clear: in a world where scaling is no longer optional, stateless architectures come to the rescue.
What Does “Stateless Frontend” Mean?
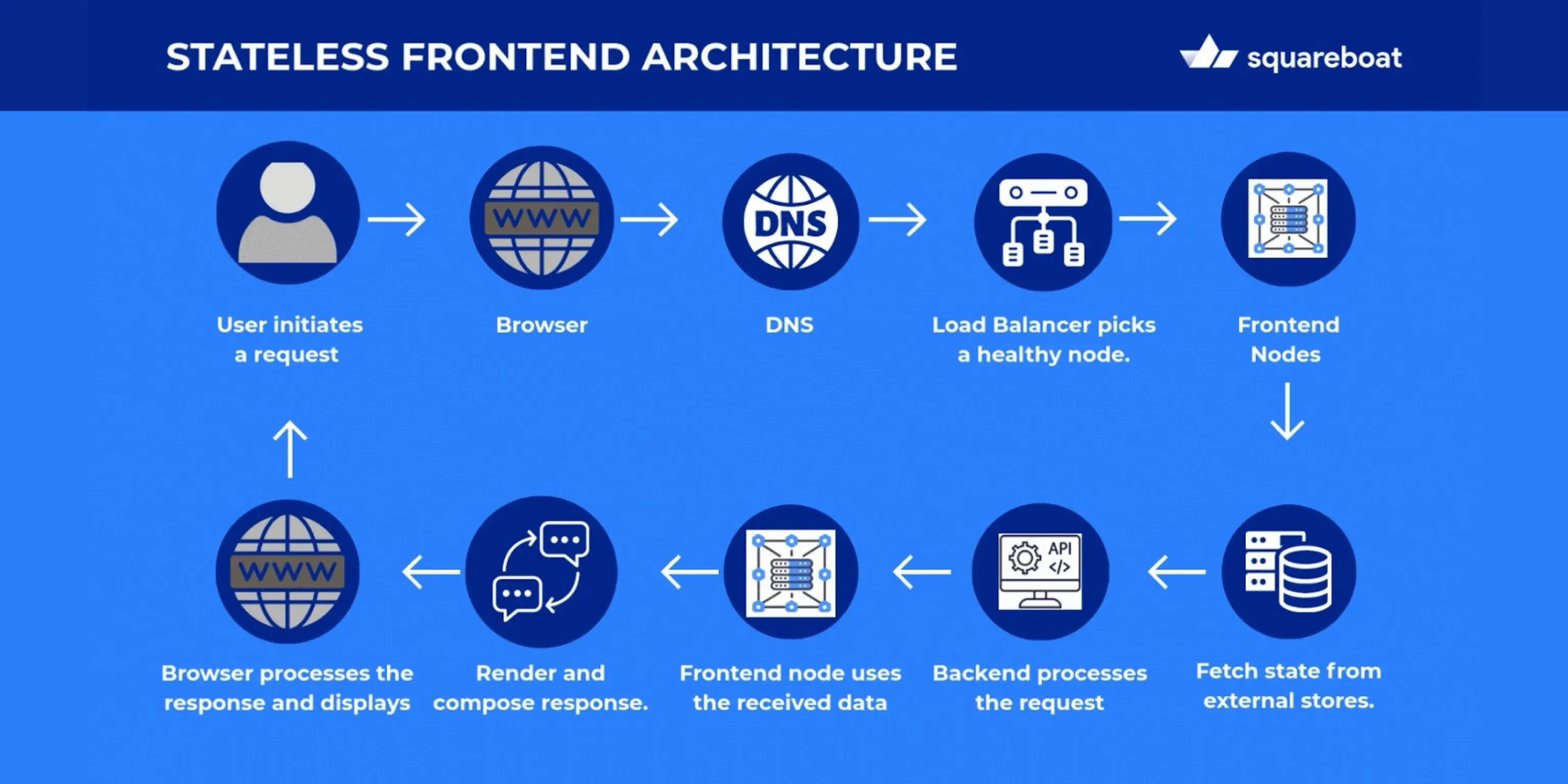
In large-scale systems, the frontend is more than just the user interface, it is the application layer closest to the user, responsible for handling interactions such as login requests, booking screens, dashboards, personalized views, etc. Its role is to accept user input, fetch the necessary context from external stores or services without holding on to any user-specific state locally.
Stateless frontend nodes are servers that do not store any user-specific state or session data locally. Instead, the state is managed externally in centralized caches such as Redis or Memcached. They hold session and user data. Stateless nodes interact with this storage to retrieve and update state as needed. Each request they handle is independent and self-contained, i.e., containing all the information the server needs to process it. The stateless nature of the nodes makes them interchangeable and disposable.
Building Fault-Tolerant Frontends
Design your frontend components and services to be as independent as possible. Squareboat specializes in architecting resilient frontend systems that ensure any single instance can handle requests independently, without relying on data from previous interactions on another server.
The frontend's architectural design ensures that enough nodes are available to manage the current load and to handle node failures. Health-check systems constantly monitor the status of nodes and automatically remove any unhealthy ones from the load balancer pool. This way, clients only connect with healthy nodes and generates a smooth and dependable experience.
This is implemented using auto-scaling groups and container orchestration platforms like Kubernetes or ECS, where new frontend pods or instances are spun up automatically to meet demand. Tools such as NGINX, HAProxy, cloud-native load balancers (AWS ALB, GCP Load Balancer), etc. manage traffic distribution and remove failing nodes in real time.
Load Balancers and Client-Side Resilience
Load balancers are vital in making the frontend fault-tolerant. They use continuous health checks to quickly identify unhealthy nodes and reroute traffic to healthy ones. In parallel, connection recovery mechanisms ensure that when a client-side connection fails it automatically attempts to reconnect to another frontend node.
This client-side resilience complements server-side redundancy that creates a recovery path that keeps the user experience intact even during failures.
Everyday Systems Built on Stateless Frontends
Think of stateless frontends like multiple ticket counters at a busy train station. No matter which counter you approach, you can buy the same ticket because all counters connect to a central system. If one counter shuts down, you simply move to another without losing your progress.
That’s exactly how stateless frontend systems work in our digital world, any node can serve you, because the state is stored externally.
Consider your everyday search engine handling billions of queries, a system so massive yet so seamless that we rarely think about the engineering behind it.
The frontend nodes serving these queries are stateless, each request is independent, and any personalization or session context is stored externally. If one node fails mid-query, the load balancer seamlessly routes the request to another healthy node, while the client retries automatically if needed.
Think about booking your daily ride for commuting. Your location, preferences, and ride history aren’t tied to a single server, they’re stored externally. This means any frontend node can process your request. If one fails while matching you to a driver, another immediately takes over, ensuring your booking goes through seamlessly.
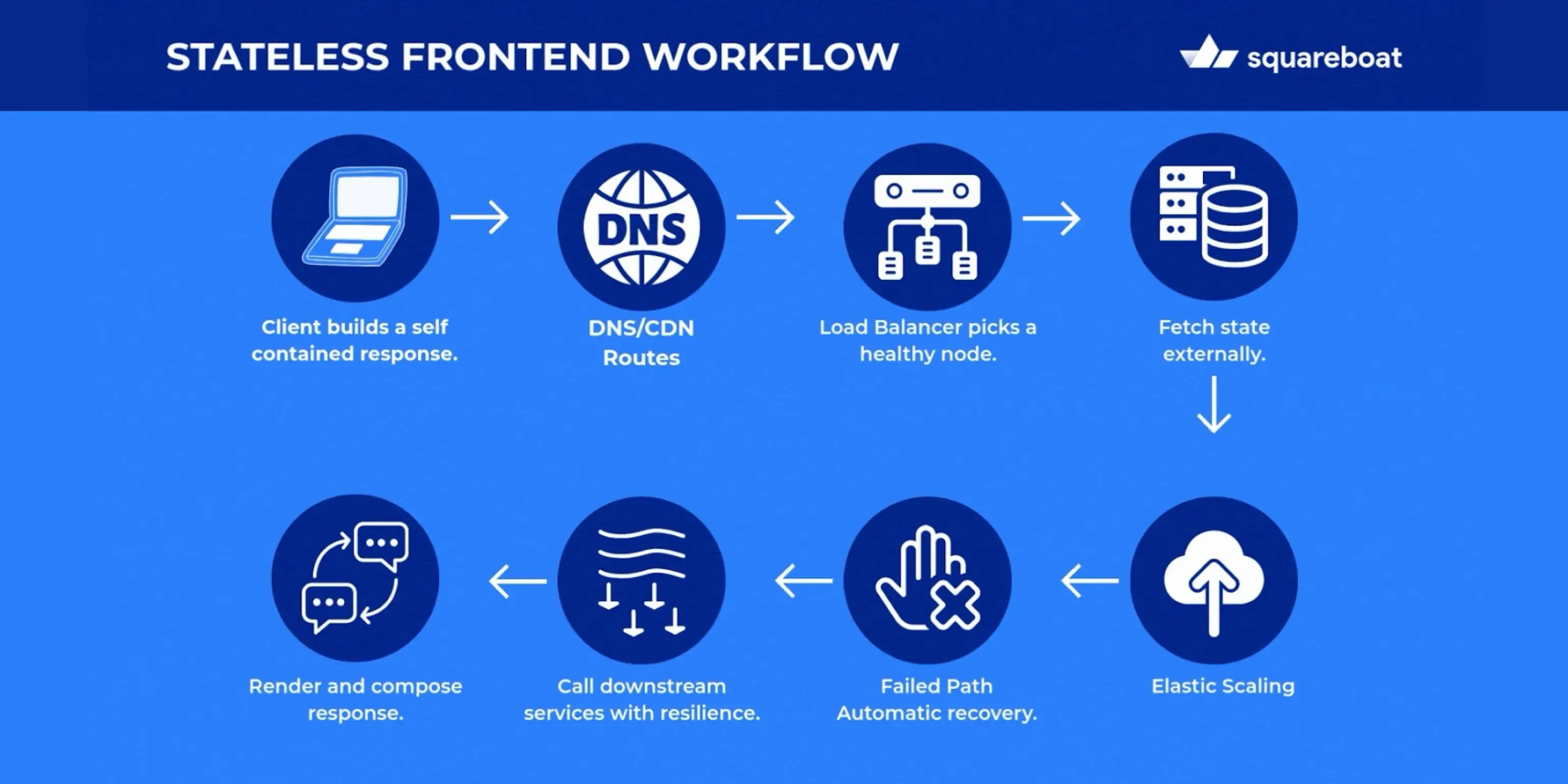
A 10-Step Stateless Frontend Flow
1. Client Builds a Self-Contained Request
Each request includes everything needed, such as authentication tokens (e.g., JWT), request parameters, and locale. There is no dependence on a prior server session.
2. DNS/CDN Routes to the Edge
Static assets like HTML, CSS, and JS are served from a CDN, while dynamic requests are forwarded to the application entry point.
3. Load Balancer Selects a Healthy Node
Health checks continuously remove unhealthy nodes from the pool. No sticky sessions are required, as all nodes are stateless and interchangeable.
4. Node Authenticates the Request
The node verifies the token (e.g., JWT signature) or retrieves minimal context from an external store like Redis or Memcached. No user session data is stored locally.
5. Fetch Transient State Externally
User-specific data, such as carts, feature flags, or preferences, is read and written from external stores. This keeps nodes disposable and independent.
6. Call Downstream Services with Resilience
Timeouts, retries, circuit breakers, and backoff mechanisms protect the UI from flaky dependencies. Optional per-request caching can further reduce load and improve performance.
7. Render and Compose the Response
The node either performs server-side rendering or returns JSON for client-side rendering. Cache headers are set so CDNs and browsers can store content safely.
8. Return Response & Log Telemetry
Structured logs, traces, and metrics (latency, errors, cache hits) are emitted. Observability does not rely on node-local state.
9. Failure Path
If a node fails during a request, the load balancer sends the request to another healthy node. Clients can automatically retry with jitter and backoff if the connection drops.
10. Elastic Scaling
Auto-scaling through platforms like Kubernetes, ECS or Auto Scaling Groups adds or removes nodes based on CPU usage, request volume or latency. There is no “drain pain” because nodes do not store session state.
Best Practices for Building Stateless Frontends
- Wisely Use External State Stores - Keep only lightweight and transient data (like sessions or carts) in Redis or Memcached. Avoid storing heavy objects that increase memory pressure. Always use TTLs and eviction policies to keep caches clean and efficient.
- Design Idempotent APIs - APIs should handle retries gracefully without causing duplicate actions. Use idempotency keys for operations like payments or orders, and rely on database constraints (like unique indexes) for extra safety. This ensures reliability even under failures.
- Embrace Observability - Implement structured logging, metrics and distributed tracing to monitor failures in real time. Correlation IDs help trace requests across services. Good observability ensures quick detection, recovery and validation of fault tolerance.
- Secure Stateless Authentication - Use token-based auth like JWT or OAuth2 with short lifetimes and refresh mechanisms. Always protect tokens with HTTPS and consider key rotation. Proper token management keeps stateless systems secure and reliable.
- Automate Scaling Policies - Tie auto-scaling to multiple signals like CPU, latency, or requests per second. Add cooldowns to avoid thrashing and define min/max limits for cost control. Automated scaling ensures smooth performance during traffic spikes.
The Trade-Offs of Frontend Fault Tolerance
Of course, fault tolerance in the frontend comes at a cost - every architectural choice introduces trade-offs in complexity, performance, and efficiency.
- While stateless applications may slow down certain types of client interactions, they unlock virtually infinite horizontal scalability.
- Statelessness enables each request to be processed in isolation, but this also means that every request must carry all the necessary context, often increasing payload size and network overhead.
- Mechanisms like health checks, load balancing and redundancy improve resilience but add operational complexity and infrastructure costs.
Final Thoughts: Why Frontend Fault Tolerance Matters
- Effortless Scalability - Stateless apps can scale horizontally with ease, as no session data is tied to individual servers. Adding or removing instances is straightforward.
- Simpler Maintenance and lower overhead - With no session tracking, the server architecture stays leaner, memory usage is reduced, and troubleshooting becomes easier.
- Greater Flexibility & Reliability – Instances can be spun up or replaced on demand, ensuring workloads are balanced and failures are absorbed without disruption.
- Consistent Experience Across Systems – Since state is managed externally, different apps and services remain in sync, delivering predictable results.
- Better User Experience – Stateless design ensures resources are shareable and consistent, for example, shared links always display the same content without relying on sessions.

Gaurav has 17+ years of experience building and managing scalable web and mobile apps end-to-end, including product design, frontend/backend development, deployment, server management, uptime, performance, and reliability.
